24小時(shí)論文定制熱線(xiàn)
24小時(shí)論文定制熱線(xiàn)
摘要
在后基因組時(shí)代,由于生物信息學(xué)的快速發(fā)展,生物信息數據呈指數級增長(cháng),生物信息數據庫系統中的數據日益龐大,這為某一專(zhuān)業(yè)領(lǐng)域的研究提供了更多的研究數據,但在浩瀚如海的數據庫中查找并篩選與研究領(lǐng)域相關(guān)的數據會(huì )耗費研究者大量的時(shí)間與精力。因此,根據自己的研究需求與特點(diǎn)建立自己的生物信息系統成為每個(gè)研究領(lǐng)域的重要課題,以便實(shí)現對數據的有效管理和分析。森林資源信息化管理可以有效提高森林可持續經(jīng)營(yíng)與經(jīng)濟生態(tài)效益,隨著(zhù)現代科技的快速發(fā)展,林業(yè)資源日趨減少,為了實(shí)現林業(yè)資源經(jīng)營(yíng)的可持續發(fā)展,需要對森林資源進(jìn)行科學(xué)有效的管理。
森林的生物信息資源的管理是森林資源信息化管理的重要方面,將宏觀(guān)與微觀(guān)相結合,形成一個(gè)由內到外、標本兼管的森林資源信息化管理系統。
本研究就此問(wèn)題設計并建立了林木生物信息系統(以毛果楊蛋白質(zhì)序列為例),用于系統地整合并存儲各數據庫(如 PIR、SwissProt、TrEMBL、NCBI 等)中林木蛋白質(zhì)序列及序列信息以及實(shí)驗中得到的楊樹(shù)蛋白質(zhì)信息以及對數據進(jìn)行簡(jiǎn)單的處理。本系統使用的 MySQL 是當下最熱門(mén)的、開(kāi)源的且具有較好的靈活性及可擴展性的數據庫關(guān)系型數據庫,而且其簡(jiǎn)單易學(xué)且使用成本低。
搭建平臺服務(wù)器主要使用了框架——Spring MVC、Ibatis:Spring 是一個(gè)十分優(yōu)秀的輕量級的 DI和 AOP 容器框架,可以很好的集成支持當前主流框架,如 Struts2、Hibernate 等,并且可以提供眾多服務(wù),如事務(wù)管理、WS 等,使用 Spring 的 IOC 容器可將對象之間的依賴(lài)關(guān)系交給 Spring,降低組件之間的耦合性,而 DI 機制則可以降低對象替換的復雜性;Ibatis 是一個(gè)十分優(yōu)秀的持久層框架,是一個(gè)半自動(dòng)化的 ORM 實(shí)現,具有很大的靈活性,易于學(xué)習使用,通過(guò)文檔和源代碼,可以較完全的掌握它的設計思路和實(shí)現。客戶(hù)端則使用了當前主流的 CSS+DIV 的布局方式,將表現和內容分離,提高頁(yè)面瀏覽速度,使用Jquery等前端框架,能更方便地處理HTML documents、events、實(shí)現動(dòng)畫(huà)效果,并且方便地為網(wǎng)站提供 AJAX 交互。
系統設計全文檢索,幫助研究人員方便快捷的檢索所需數據。同時(shí),本數據庫平臺實(shí)現了上傳功能,可以方便研究人員上傳自己研究得到的數據,實(shí)現數據共享。另外提供一些有用的分析功能來(lái)方便研究者分析蛋白質(zhì)序列,如通過(guò)本地 BLAST 搜索本地數據庫中的同源蛋白質(zhì)序列,利用蛋白質(zhì)理化性質(zhì)分析蛋白質(zhì)氨基酸組成、親疏水性、等電點(diǎn)等,支持用戶(hù)對蛋白質(zhì)序列進(jìn)行編碼:簡(jiǎn)單編碼和 V 型編碼,系統還提供蛋白質(zhì)序列二級結構的預測功能。
關(guān)鍵詞:林木生物信息、楊樹(shù)蛋白質(zhì)、JAVA、BLAST、蛋白質(zhì)編碼、二級結構預測
ABSTRACT
Because of the rapid development of bioinformatics, biological information data exponentially, biological information data in a database system is increasingly large in post genome era. Therefore, they build their own biological information system according to their own research needs and characteristics and this Biological information system becomes an important issue in the field of each research, in order to realize the effective management and analysis of the data. Forest resources information management can effectively improve the ecological benefits of forest sustainable management and economic, but it still has difficulty in controlling the disease of the body to produce trees. This needs us to carry on research from trees and find the key to disease. And then, from the perspective of the essence, take measures effectively to solve forest disease, combining macro and micro, formation and symptoms of forest resource information management.
This study is to design and set up forest biological information system (populus trichocarpa protein sequences, for example), is used to systematically integrate and store the database (e.g., PIR, SwissProt, TrEMBL, NCBI) trees in protein sequence and protein sequence information, and the experiment of poplar information and simple data processing.
MySQL used by the system is the most popular, and has good flexibility and scalability to open source database, relational database, and its easy to learn and the cost is low. To build platform server mainly USES the framework - Spring MVC, Ibatis: Spring is a very good lightweight DI container and AOP framework, can very good integration support the current mainstream framework, such as struts 2, Hibernate, etc., and can provide many services, such as transaction management, WS, using Spring IOC container can be dependencies between objects to the Spring, to reduce coupling between components, whereas DI mechanism can reduce the complexity of the object to replace; Ibatis is an excellent persistence layer framework, a semi-automated ORM implementation. It has a great deal of flexibility. While it’s easy to learn to use. Through the document and source code, we can be fully grasp its design idea and implementation. Client is using the current mainstream of CSS + DIV layout, the separation performance and content, increase the speed of page views, such as using Jquery front frame, can more easily handle HTML documents, events, to achieve animation effects, and convenient to provide AJAX interaction for the web site.
Full text retrieval system design, convenient and quick to help researchers can retrieve the required data. At the same time, the database platform can realize the function of uploading, researchers can upload their data, realize data sharing. Meanwhile it provides some useful analysis function to convenient researchers analyze protein sequences, such as through local BLAST search local homologous protein sequences in the database, using protein protein amino acid composition, physical and chemical properties analysis distinguishes water-based, isoelectric point, etc., it also supports user to encode protein sequence: simple encoding and V coding, and system also provides secondary structure prediction of protein sequences.
Key words: forest biological information; poplar protein; JAVA; BLAST; protein coding;Secondary structure prediction
信息系統(Information system)是基于信息流處理的人機一體化系統[1],由計算機軟件、計算機硬件設施、網(wǎng)絡(luò )和通信技術(shù)、數據信息、用戶(hù)信息和規章制度構成,是建立在信息技術(shù)基礎上的一種進(jìn)行組織和管理的手段,能夠實(shí)現輸入、輸出、存儲、處理和控制等功能[2]。它是 20 世紀中期信息科學(xué)、管理科學(xué)、系統科學(xué)、計算機科學(xué)、決策科學(xué)等相互交叉融合發(fā)展起來(lái)的新興學(xué)科,能夠最大極限地發(fā)揮計算機技術(shù)和網(wǎng)絡(luò )通信技術(shù)的使用,通過(guò)統計公司所具有的人力、物力、財力、設施、技術(shù)等數據信息[3],建立完整、有效的信息數據庫,對數據信息進(jìn)行加工和處理,將整理好的各類(lèi)信息資料及時(shí)反饋給管理人員,便于決策者加強企業(yè)信息管理,做出正確決策以便不斷提高企業(yè)的管理水平和經(jīng)濟效益[4]。信息系統從其系統的特點(diǎn)以及發(fā)展來(lái)分類(lèi),可劃分成管理信息系統、數據處理系統、決策支持系統、虛擬辦公系統和專(zhuān)家系統五種[5]。
信息系統的發(fā)展與計算機技術(shù)、網(wǎng)絡(luò )通訊技術(shù)、數據庫技術(shù)以及硬件設施的提升密切相關(guān)。自1946 年第一臺電子計算機誕生,信息系統的發(fā)展在過(guò)去 70 年里經(jīng)過(guò)了由單機到網(wǎng)絡(luò ),由低級到高級,由電子數據處理系統(EDPS)到管理信息系統(MIS)、再到?jīng)Q策支持系(DSS),由數據處理到智能處理的過(guò)程[5-9]:電子數據處理系統階段,首要功能是用于處理日常的工作事務(wù),用計算機取代人工計算與管理,按時(shí)為管理者提供一系列有效的數據信息。管理信息系統階段最突出的特征是信息高度集中化,可以快速處理高度集中的數據與信息并對其進(jìn)行統一使用;另一主要特征是采用量化的科學(xué)管理手段,運用預測、優(yōu)化規劃、管理、調控等技術(shù)進(jìn)行決策支持。決策支持系統階段是信息系統發(fā)展過(guò)程中產(chǎn)生的更高層次、更先進(jìn)的系統,可以為各級決策管理部門(mén)提供問(wèn)題分析、建模、決策模擬及方案解決的過(guò)程和環(huán)境,將各種數據信息以及分析手段融合使用,有效提高決策者的決策水準與效率。信息系統在這三大階段的發(fā)展中不停探究并逐步完善。1993 年,Internet 上出現 www(萬(wàn)維網(wǎng)),為信息系統的網(wǎng)絡(luò )化創(chuàng )造了絕佳的發(fā)展前提[5,10]。
從當前國際信息系統的發(fā)展情況來(lái)看,全球信息化正在引發(fā)技術(shù)變革,加快信息化技術(shù)發(fā)展,已成為當今全球趨勢,信息系統是對信息進(jìn)行有效加工管理的有效手段,它的建立能夠對全球信息化發(fā)展起到重要支撐作用,因此信息系統全球化是全球信息化發(fā)展的有效途徑。當前的信息系統正邁向網(wǎng)絡(luò )化、集成化和知識信息系統、智能經(jīng)濟系統的形式[11,12]:信息系統網(wǎng)絡(luò )化發(fā)展為電子商務(wù)發(fā)展提供了強有力的技術(shù)支持,電子商務(wù)是互聯(lián)網(wǎng)上建立的世界電子市場(chǎng);伴隨全球經(jīng)濟一體化,當今經(jīng)濟形態(tài)正逐漸向知識經(jīng)濟方向發(fā)展,信息系統的結構、處理能力等都應符合知識經(jīng)濟發(fā)展的要求。
知識信息系統除了應具有信息系統的所有功能外,其核心功能是專(zhuān)家系統功能;智能信息系統能夠處理非結構化業(yè)務(wù)并且處于決策過(guò)程的核心位置,可以為人作向導,知識創(chuàng )新功能是其所特有的功能;當信息系統以基于神經(jīng)網(wǎng)絡(luò )神經(jīng)元構建、遺傳算法的智能網(wǎng)為主發(fā)展時(shí),信息系統對人類(lèi)生產(chǎn)生活的貢獻會(huì )更大[13,14]。
生物信息系統的主要功能是生物信息數據的收集、整理、存儲、管理與分析,其主要任務(wù)有兩個(gè),一是管理好后基因組時(shí)代中產(chǎn)生的海量生物信息數據,二是利用好這些數據,研究發(fā)現新規律,產(chǎn)生社會(huì )價(jià)值。數據庫是生物信息系統的核心研究?jì)热荩瑖獾陌l(fā)達國家在這方面起步較早,有一些機構在生物信息學(xué)領(lǐng)域已經(jīng)處于主導地位了,它們都開(kāi)發(fā)了相關(guān)的數據庫、系統等。如美國國家生物技術(shù)信息中心(National Center for Biotechnology Information, NCBI)建立并維護的 GenBank數據庫,歐洲分子生物學(xué)實(shí)驗室(European Molecular Biology Laboratory, EMBL)的數據庫和日本的DNA 數據庫(DNA Data Bank of Japan, DDBJ)都是被普遍使用的綜合性一級核酸數據庫系統。隨著(zhù)高通量技術(shù)的發(fā)展,大數據的存儲、傳輸與處理技術(shù)的發(fā)展,軟件和算法的提升,數據庫系統的綜合化、S/C 模式的構建使含有生物信息數據庫、分析工具以及生物信息文獻資料等在內的生物信息系統成為研究人類(lèi)、動(dòng)物、植物等領(lǐng)域的有力工具及手段,從新基因的發(fā)現與測定、蛋白質(zhì)序列預測其結構與功能、研究篩選疫苗到新藥的研發(fā)全都離不開(kāi)生物信息系統,幾乎覆蓋了生命科學(xué)研究的各個(gè)領(lǐng)域,尤其在人類(lèi)、動(dòng)物、植物等領(lǐng)域的應用[15]。
1995 年 5 月 Sun Microsystems 公司在 Sun world 會(huì )議上正式對外發(fā)布 Java 和 HotJava瀏覽器。IBM、Adobe、Netscape、Oracle、Apple 以及微軟等各大公司都暫停自己的開(kāi)發(fā)項目,爭相購買(mǎi) Java 使用許可證,并為自己的產(chǎn)品開(kāi)發(fā)了相應的 Java 平臺[58,59]。2006年 Sun Microsystems 公司宣布:Java 技術(shù)將免費對外發(fā)布,從 2007 年 3 月起,世界各地所有的開(kāi)發(fā)人員都可以修改 Java 的源代碼[60]。Java 語(yǔ)言具有面向對象性、動(dòng)態(tài)性、分布式性、安全性、健壯性、高性能性、多線(xiàn)程性、跨平臺等優(yōu)點(diǎn)。Java 與 Matlab 相比,Java 代碼是完全免費開(kāi)源的,與 R 語(yǔ)言相比具有嵌入到 Java 程序更方便的優(yōu)勢;與 Perl相比,Java 的執行效率更高。近年來(lái),得益于其開(kāi)源、可重復利用和面向對象的優(yōu)勢,Java 在生物信息學(xué)中得到了廣泛的應用[61,62]。
目前,針對生物信息學(xué)發(fā)展中存在的種種問(wèn)題,研究者已經(jīng)用 Java 語(yǔ)言開(kāi)發(fā)了諸如BioJava、 Cytoscape 等[60]很多軟件系統工具。BioJava 是 Java 平臺下的一個(gè)開(kāi)源工程項目,主要是用來(lái)處理生物信息數據,如序列處理,文件解析,ACeDB,DAS,CORBA協(xié)同性的訪(fǎng)問(wèn),動(dòng)態(tài)程序等等,并且能做一些簡(jiǎn)單的統計程序。BioJava 主要功能覆蓋基因組、蛋白質(zhì)組、算法和 BioSQL 這方面,可對基因序列轉換、注釋、BLAST&FASTA;計算蛋白質(zhì)等電點(diǎn)、蛋白結構預測、蛋白質(zhì)序列比對等;提供一些常用算法,如遺傳算法、HMM、動(dòng)態(tài)規劃等;提供生物學(xué)數據庫支持,如一般的序列數據庫、數據庫類(lèi)型和Ontology 數據庫等。 Cytoscape 是 Java 語(yǔ)言編寫(xiě)的用于繪制和分析各類(lèi)生物信息數據網(wǎng)絡(luò ),針對不同類(lèi)型的網(wǎng)絡(luò )開(kāi)發(fā)出的基于 Cytoscape 的插件大概有數百種。此外,作為生物信息系統領(lǐng)域中最權威和使用最普遍的平臺--美國國立生物技術(shù)信息中心(NationalCenter for Biotechnology Information, NCBI)[63]也提供了相應的 Java API,因此,Java成為生物信息系統研究中最有效的開(kāi)發(fā)語(yǔ)言。
林木生物信息系統效果演示:
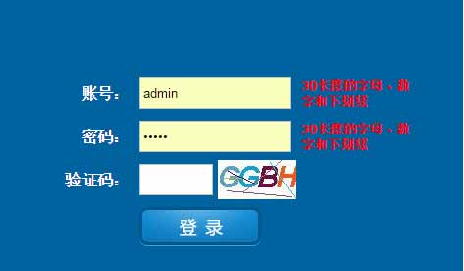
林木生物信息系統登錄界面
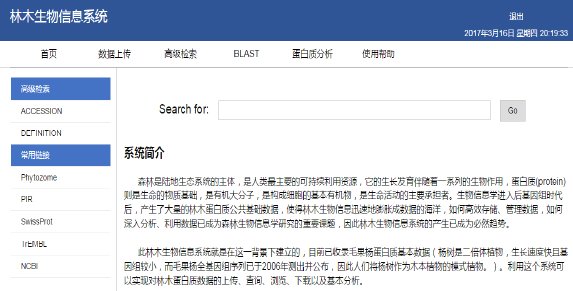
林木生物信息系統首頁(yè)
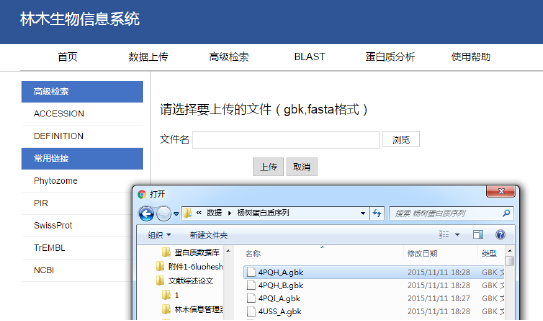
選擇上傳文件
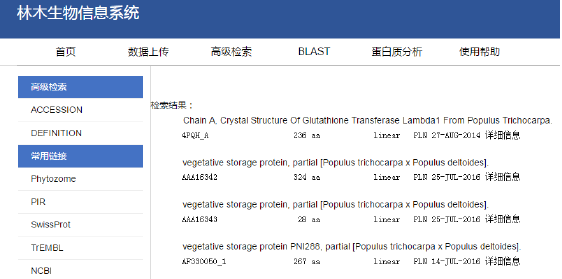
Populus Trichocarpa 檢索結果
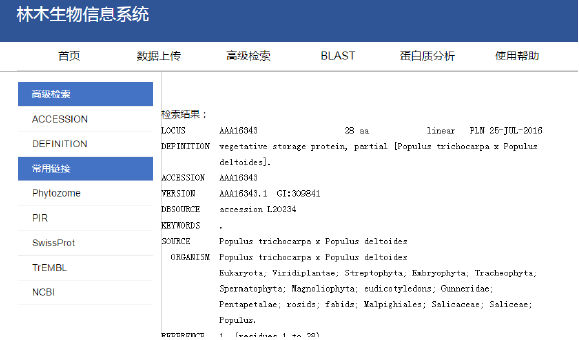
蛋白質(zhì)詳細信息
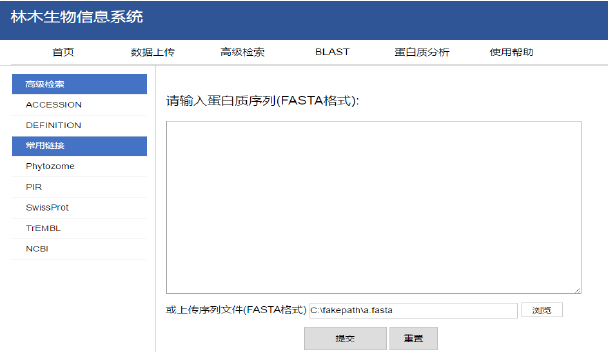
本地 BLAST 比對
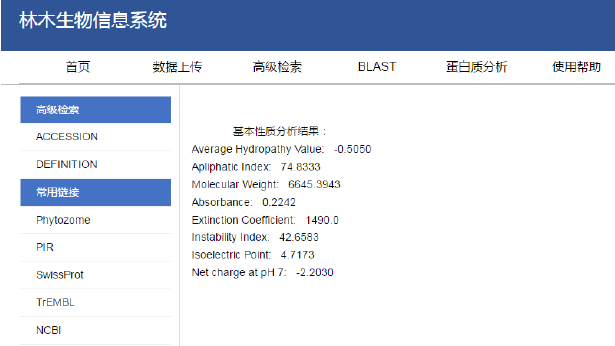
蛋白質(zhì)基本性質(zhì)分析結果
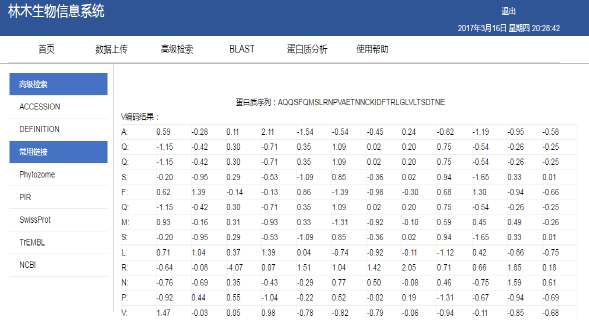
蛋白質(zhì)序列 V 型編碼結果
目錄
摘 要
1 文獻綜述
1.1 信息系統
1.1.1 信息系統概念
1.1.2 信息系統的發(fā)展
1.2 生物信息系統
1.2.1 人類(lèi)生物信息系統
1.2.2 動(dòng)物生物信息系統
1.2.3 植物生物信息系統
1.3 JAVA、BIOJAVA 在生物信息系統中的應用
2 引言
3 材料與方法
3.1 數據來(lái)源
3.1.1 蛋白質(zhì)序列數據庫
3.1.2 蛋白質(zhì)結構數據庫
3.1.3 蛋白質(zhì)序列二級數據庫
3.2 數據收集與整理
3.3 林木生物信息系統數據庫設計
3.3.1 需求分析
3.3.1 數據庫系統設計
3.4 林木生物信息系統功能設計
3.4.1 數據上傳
3.4.2 BLAST 比對工具
3.4.3 蛋白質(zhì)理化性質(zhì)分析工具
3.4.4 蛋白質(zhì)編碼
3.4.5 蛋白質(zhì)二級結構預測
4 結果與分析
4.1 系統開(kāi)發(fā)環(huán)境
4.1.1 系統軟件開(kāi)發(fā)環(huán)境
4.1.2 系統硬件開(kāi)發(fā)環(huán)境
4.2 用戶(hù)登錄界面及系統主界面
4.3 數據上傳功能
4.4 數據檢索功能
4.4.1 高級檢索
4.4.2 快速檢索
4.5 數據分析功能
4.5.1 BLAST 比對
4.5.2 蛋白質(zhì)理化性質(zhì)分析
4.5.3 蛋白質(zhì)序列編碼
4.5.4 蛋白質(zhì)二級結構預測
5 結論與討論
5.1 結論
5.2 討論
參考文獻
英文摘要
(如您需要查看本篇畢業(yè)設計全文,請您聯(lián)系客服索取)